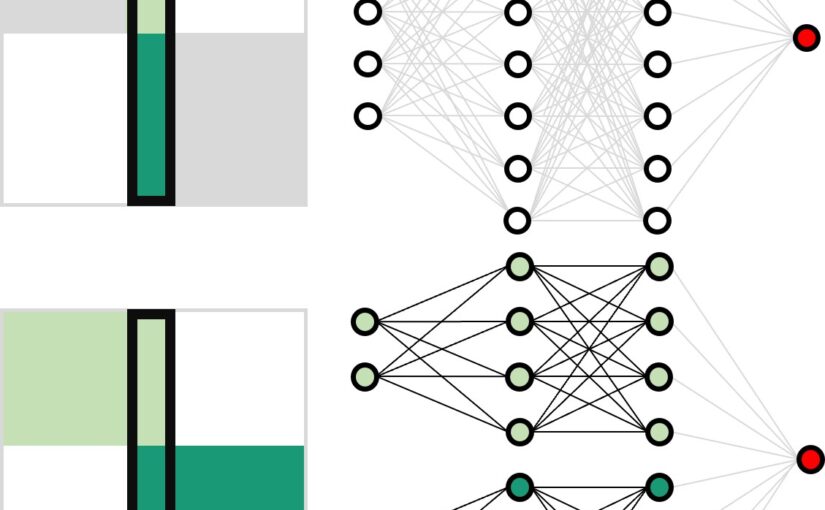
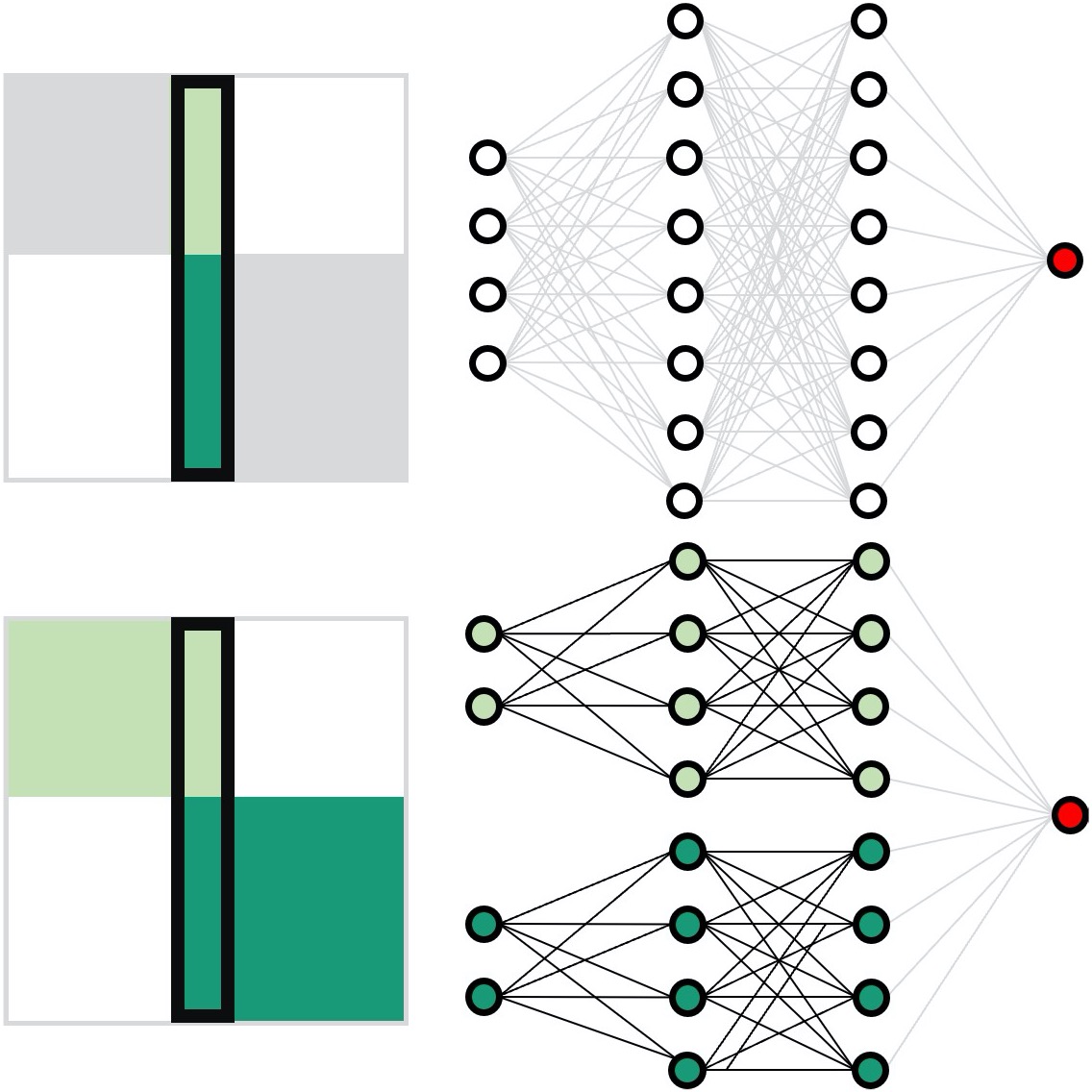
Working principles for training neural networks with highly incomplete dataset: vanilla (upper panel) vs GapNet (lower panel) (Image by Yu-Wei Chang.)GapNet: Neural network training with highly incomplete datasets
Presentation in group meeting of Prof. Michael Strano, Department of Chemical Engineering, Massachusetts Institute of Technology, USA and DiSTAP, Singapore-MIT Alliance for Research and Technology, Singapore. Date: 23 February 2024
Neural network training requires complete data. We have introduced GapNet, which can train neural networks with incomplete data, using medical data. This approach can be generalized for integrating spectrum data across different frequency ranges, allowing the neural network to combine important information from diverse spectrum datasets.
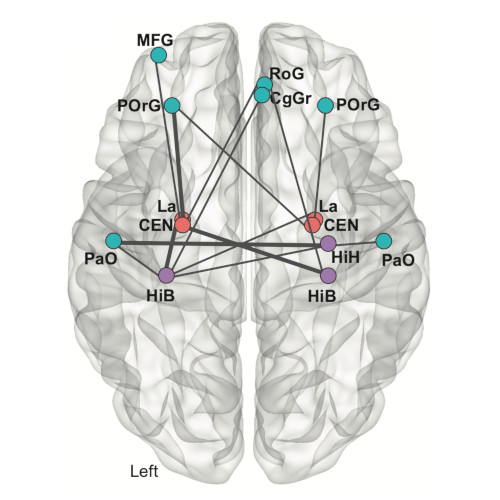
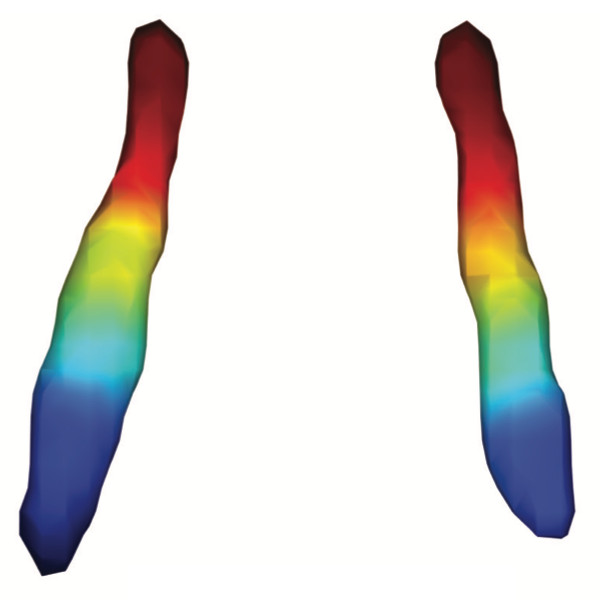
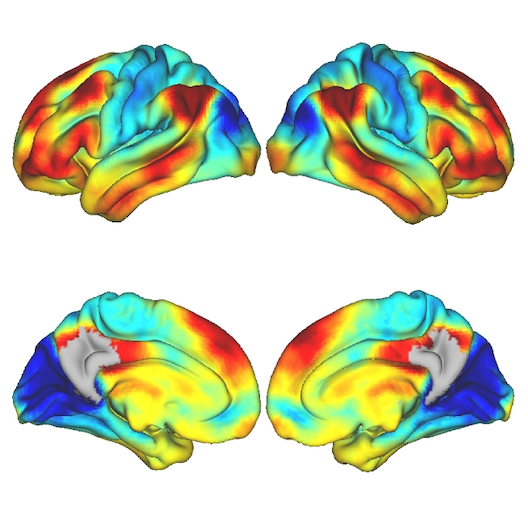
Brain region connectivity. (Image by the Authors of the manuscript.)Connecting genomic results for psychiatric disorders to human brain cell types and regions reveals convergence with functional connectivity
Shuyang Yao, Arvid Harder, Fahimeh Darki, Yu-Wei Chang , Ang Li, Kasra Nikouei, Giovanni Volpe, Johan N Lundström, Jian Zeng , Naomi Wray, Yi Lu, Patrick F Sullivan, Jens Hjerling-Leffler
medRxiv: 10.1101/2024.01.18.24301478
Understanding the temporal and spatial brain locations etiological for psychiatric disorders is essential for targeted neurobiological research. Integration of genomic insights from genome-wide association studies with single-cell transcriptomics is a powerful approach although past efforts have necessarily relied on mouse atlases. Leveraging a comprehensive atlas of the adult human brain, we prioritized cell types via the enrichment of SNP-heritabilities for brain diseases, disorders, and traits, progressing from individual cell types to brain regions. Our findings highlight specific neuronal clusters significantly enriched for the SNP-heritabilities for schizophrenia, bipolar disorder, and major depressive disorder along with intelligence, education, and neuroticism. Extrapolation of cell-type results to brain regions reveals important patterns for schizophrenia with distinct subregions in the hippocampus and amygdala exhibiting the highest significance. Cerebral cortical regions display similar enrichments despite the known prefrontal dysfunction in those with schizophrenia highlighting the importance of subcortical connectivity. Using functional MRI connectivity from cases with schizophrenia and neurotypical controls, we identified brain networks that distinguished cases from controls that also confirmed involvement of the central and lateral amygdala, hippocampal body, and prefrontal cortex. Our findings underscore the value of single-cell transcriptomics in decoding the polygenicity of psychiatric disorders and offer a promising convergence of genomic, transcriptomic, and brain imaging modalities toward common biological targets.
Logo of the Gun and Bertil Stohne’s Foundation. (Image from the Foundation’s website.)
Yu-Wei Chang received one of the Gun and Bertil Stohnes Foundation Prizes for PhD students, with his recent research focusing on deep learning analysis of longitudinal tau pathology. The price consists in 100000 SEK given to one – or shared between two – student(s) at a Swedish university.
The Gun and Bertil Stohnes Foundation awards this prize to research projects in geriatrics that the Board deems of exceptional interest and value.
Anna Canal Garcia, from Karolinska Institutet and supervised by Prof. Joana B. Pereira, is the other recipient of this award. Anna’s research focuses on the intricate multilayer network analysis of brain neuroimaging data.
Opponent Saikat Chatterjee (on Zoom), Yu-Wei Chang (left), and PhD co-supervisor Joana B. Pereira (right). (Photo by P.-J. Chien.)Yu-Wei Chang completed the first half of his doctoral studies and he defended his half-time on the 3rd of November 2023.
The presentation was conducted in a hybrid format, with part of the audience present in the Nexus room and the remainder connected through Zoom. The seminar comprised a presentation covering both his completed and planned projects, followed by a discussion and questions posed by his opponent, Prof. Saikat Chatterjee.
The presentation commenced with an overview of his concluded projects. The first project involves handling incomplete medical datasets using neural networks and is published in ‘Machine Learning: Science and Technology.‘ It then transitioned to his second project, focusing on the development of software for brain connectivity analysis using multilayer graphs and deep learning. The corresponding repository is accessible on GitHub. In the final segment, he outlined the proposed continuation of his PhD, discussing an ongoing project centered around the deep learning analysis of longitudinal brain neural imaging data.
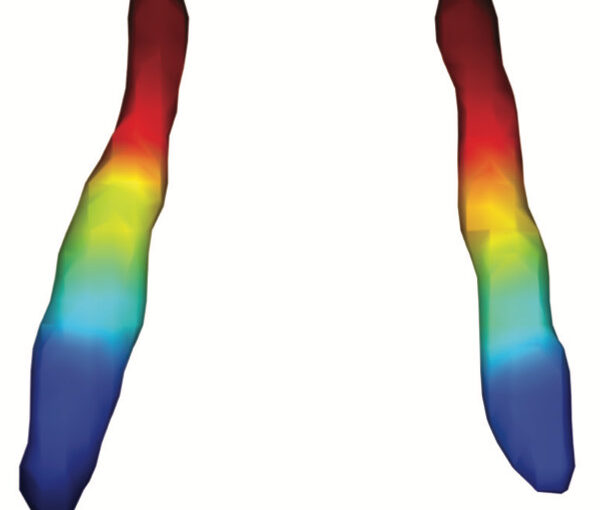
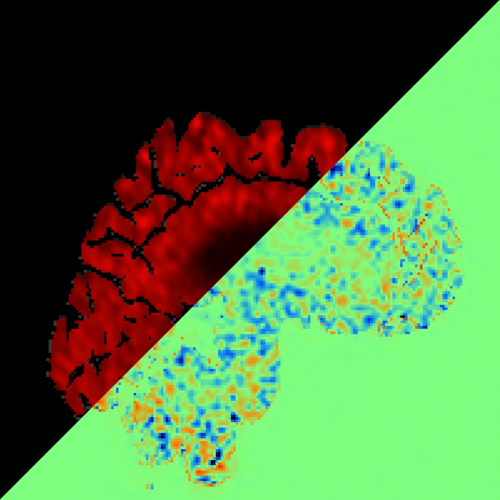
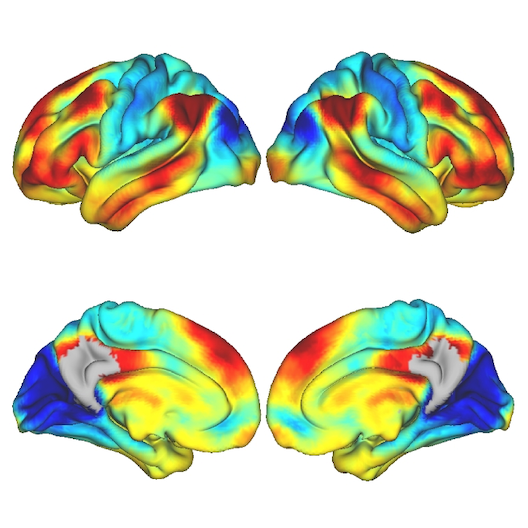
Average functional gradients of the locus coeruleus in the CamCAN 3T dataset. (Image from the publication.)Age-related differences in the functional topography of the locus coeruleus and their implications for cognitive and affective functions
Dániel Veréb, Mite Mijalkov, Anna Canal-Garcia, Yu-Wei Chang, Emiliano Gomez-Ruiz, Blanca Zufiria Gerboles, Miia Kivipelto, Per Svenningsson, Henrik Zetterberg, Giovanni Volpe, Matthew Betts, Heidi IL Jacobs, Joana B Pereira
eLife 12, RP87188 (2023)
doi: 10.7554/eLife.87188.3
The locus coeruleus (LC) is an important noradrenergic nucleus that has recently attracted a lot of attention because of its emerging role in cognitive and psychiatric disorders. Although previous histological studies have shown that the LC has heterogeneous connections and cellular features, no studies have yet assessed its functional topography in vivo, how this heterogeneity changes over aging, and whether it is associated with cognition and mood. Here, we employ a gradient-based approach to characterize the functional heterogeneity in the organization of the LC over aging using 3T resting-state fMRI in a population-based cohort aged from 18 to 88 years of age (Cambridge Centre for Ageing and Neuroscience cohort, n=618). We show that the LC exhibits a rostro-caudal functional gradient along its longitudinal axis, which was replicated in an independent dataset (Human Connectome Project [HCP] 7T dataset, n=184). Although the main rostro-caudal direction of this gradient was consistent across age groups, its spatial features varied with increasing age, emotional memory, and emotion regulation. More specifically, a loss of rostral-like connectivity, more clustered functional topography, and greater asymmetry between right and left LC gradients was associated with higher age and worse behavioral performance. Furthermore, participants with higher-than-normal Hospital Anxiety and Depression Scale (HADS) ratings exhibited alterations in the gradient as well, which manifested in greater asymmetry. These results provide an in vivo account of how the functional topography of the LC changes over aging, and imply that spatial features of this organization are relevant markers of LC-related behavioral measures and psychopathology.
The proposed method enables accurate synthesis of longitudinal tau pathology. (Image by Y.-W. Chang.)Synthesizing tau pathology from structural brain imaging using deep learning Yu-Wei Chang, Giovanni Volpe, Joana B Pereira Date: 22 August 2023 Time: 10:15 AM PDT
In vivo tau-positron emission tomography (PET) is crucial for determining the stage of Alzheimer’s disease (AD). However, this method is expensive, not widely available, and exposes patients to ionizing radiation, which poses a carcinogenic risk. To address this issue, I’ll present our proposed method, a deep-learning synthesis approach for follow-up tau-PET brain images from baseline tau-PET images using a generative adversarial network (GAN). This technique has the potential to provide valuable insights into the progression of AD, the effectiveness of new treatments, and more accurate diagnosis of the disease.
The Soft Matter Lab participates to the SPIE Optics+Photonics conference in San Diego, CA, USA, 20-24 August 2023, with the presentations listed below.
Agnese Callegari: Playing with active matter
21 August 2023 • 4:05 PM – 4:20 PM PDT | Conv. Ctr. Room 6D
Giovanni Volpe is also co-author of the presentations:
Jiawei Sun (KI): (Poster) Assessment of nonlinear changes in functional brain connectivity during aging using deep learning
21 August 2023 • 5:30 PM – 7:00 PM PDT | Conv. Ctr. Exhibit Hall A
Blanca Zufiria Gerbolés (KI): (Poster) Exploring age-related changes in anatomical brain connectivity using deep learning analysis in cognitively healthy individuals
21 August 2023 • 5:30 PM – 7:00 PM PDT | Conv. Ctr. Exhibit Hall A
Mite Mijalkov (KI): Uncovering vulnerable connections in the aging brain using reservoir computing
22 August 2023 • 9:15 AM – 9:30 AM PDT | Conv. Ctr. Room 6C
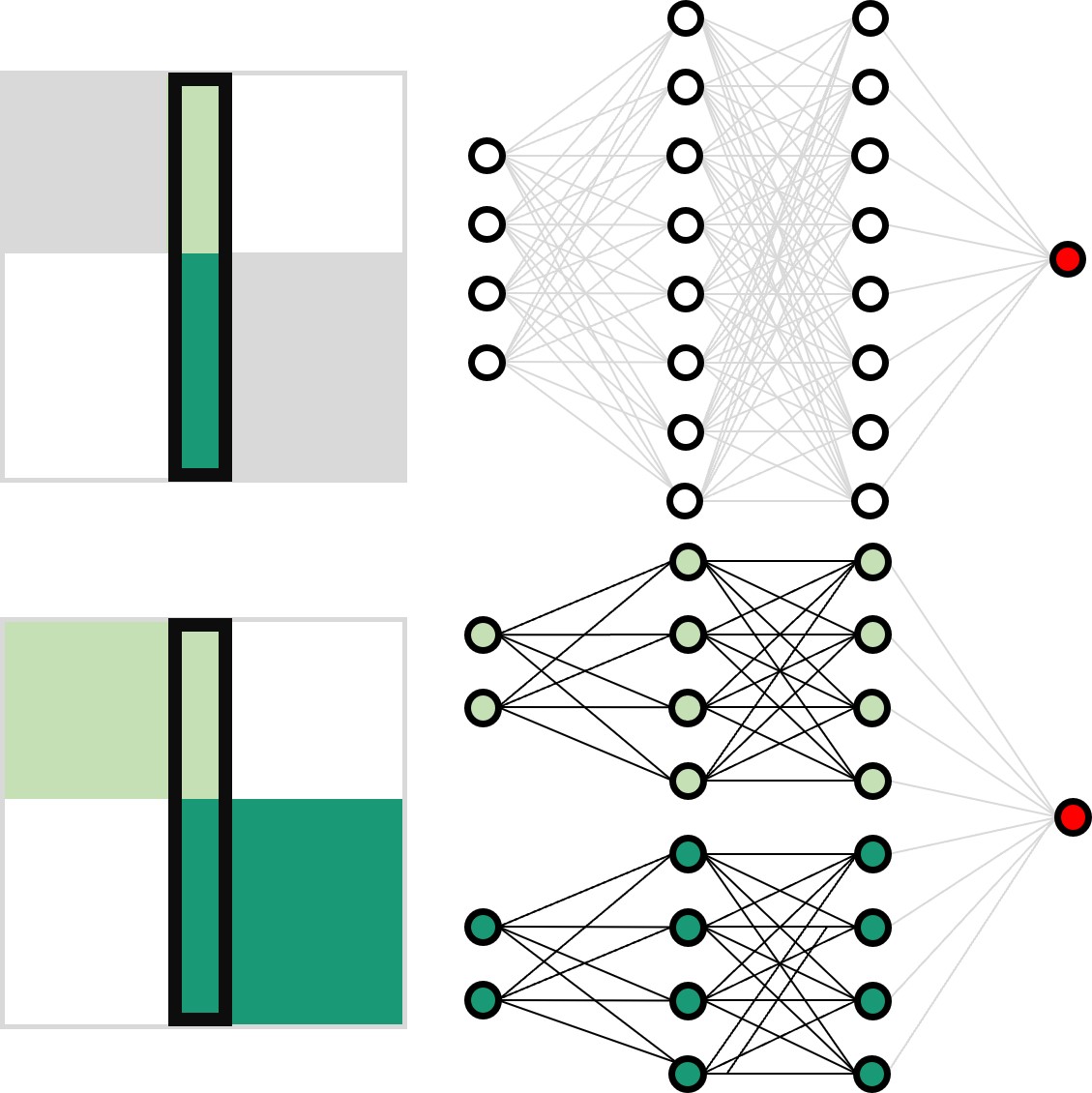
Working principles for training neural networks with highly incomplete dataset: vanilla (upper panel) vs GapNet (lower panel) (Image by Y.-W. Chang.)
Training of neural network with incomplete medical datasets
Yu-Wei Chang
Neural network training and validation rely on the availability of large high-quality datasets. However, in many cases, only incomplete datasets are available, particularly in health care applications, where each patient typically undergoes different clinical procedures or can drop out of a study. Here, we introduce GapNet, an alternative deep-learning training approach that can use highly incomplete datasets without overfitting or introducing artefacts. Using two highly incomplete real-world medical datasets, we show that GapNet improves the identification of patients with underlying Alzheimer’s disease pathology and of patients at risk of hospitalization due to Covid-19. Compared to commonly used imputation methods, this improvement suggests that GapNet can become a general tool to handle incomplete medical datasets.
Spatial maps depicting the strongest connections from the medial parietal cortex to other cortical and subcortical areas in the PREVENT-AD cohort. (Reproduced from the publication.)Functional gradients of the medial parietal cortex in a healthy cohort with family history of sporadic Alzheimer’s disease
Dániel Veréb, Mite Mijalkov, Yu-Wei Chang, Anna Canal-Garcia, Emiliano Gomez-Ruis, Anne Maass, Sylvia Villeneuve, Giovanni Volpe Joana B. Pereira
Alzheimer’s Research & Therapy 15, 82 (2023)
doi: 10.1186/s13195-023-01228-3
Background
The medial parietal cortex is an early site of pathological protein deposition in Alzheimer’s disease (AD). Previous studies have identified different subregions within this area; however, these subregions are often heterogeneous and disregard individual differences or subtle pathological alterations in the underlying functional architecture. To address this limitation, here we measured the continuous connectivity gradients of the medial parietal cortex and assessed their relationship with cerebrospinal fluid (CSF) biomarkers, ApoE ε4 carriership and memory in asymptomatic individuals at risk to develop AD.
Methods
Two hundred sixty-three cognitively normal participants with a family history of sporadic AD who underwent resting-state and task-based functional MRI using encoding and retrieval tasks were included from the PREVENT-AD cohort. A novel method for characterizing spatially continuous patterns of functional connectivity was applied to estimate functional gradients in the medial parietal cortex during the resting-state and task-based conditions. This resulted in a set of nine parameters that described the appearance of the gradient across different spatial directions. We performed correlation analyses to assess whether these parameters were associated with CSF biomarkers of phosphorylated tau181 (p-tau), total tau (t-tau), and amyloid-ß1-42 (Aß). Then, we compared the spatial parameters between ApoE ε4 carriers and noncarriers, and evaluated the relationship between these parameters and memory.
Results
Alterations involving the superior part of the medial parietal cortex, which was connected to regions of the default mode network, were associated with higher p-tau, t-tau levels as well as lower Aß/p-tau levels during the resting-state condition (p < 0.01). Similar alterations were found in ApoE ε4 carriers compared to non-carriers (p < 0.003). In contrast, lower immediate memory scores were associated with changes in the middle part of the medial parietal cortex, which was connected to inferior temporal and posterior parietal regions, during the encoding task (p = 0.001). No results were found when using conventional connectivity measures.
Conclusions
Functional alterations in the medial parietal gradients are associated with CSF AD biomarkers, ApoE e4 carriership, and lower memory in an asymptomatic cohort with a family history of sporadic AD, suggesting that functional gradients are sensitive to subtle changes associated with early AD stages.
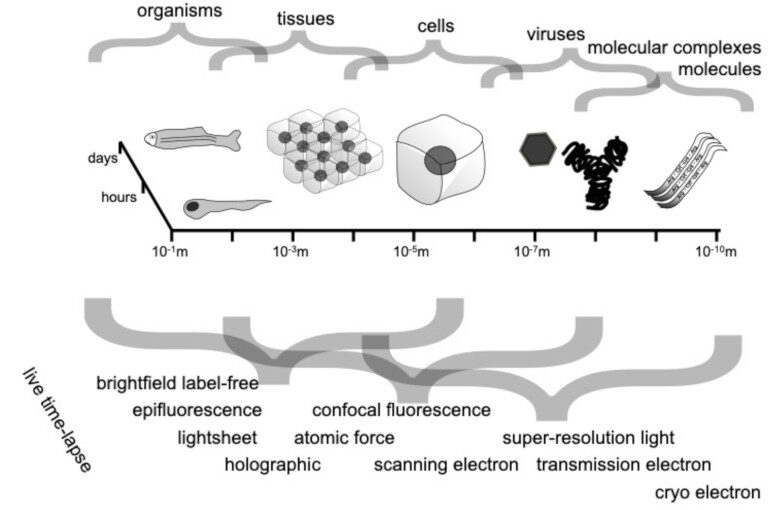
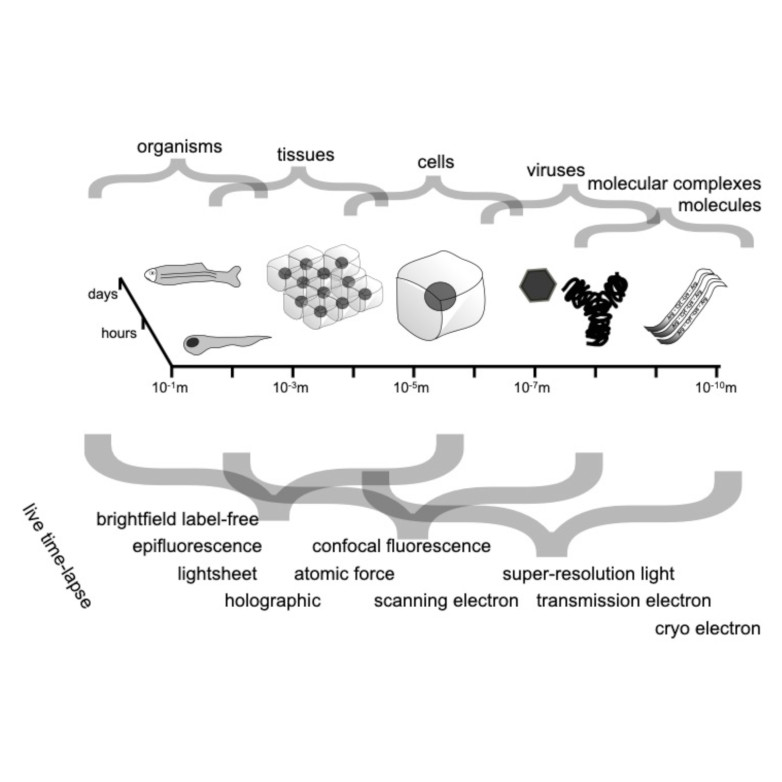
Spatio-temporal spectrum diagram of microscopy techniques and their applications. (Image by the Authors of the manuscript.)Roadmap on Deep Learning for Microscopy
Giovanni Volpe, Carolina Wählby, Lei Tian, Michael Hecht, Artur Yakimovich, Kristina Monakhova, Laura Waller, Ivo F. Sbalzarini, Christopher A. Metzler, Mingyang Xie, Kevin Zhang, Isaac C.D. Lenton, Halina Rubinsztein-Dunlop, Daniel Brunner, Bijie Bai, Aydogan Ozcan, Daniel Midtvedt, Hao Wang, Nataša Sladoje, Joakim Lindblad, Jason T. Smith, Marien Ochoa, Margarida Barroso, Xavier Intes, Tong Qiu, Li-Yu Yu, Sixian You, Yongtao Liu, Maxim A. Ziatdinov, Sergei V. Kalinin, Arlo Sheridan, Uri Manor, Elias Nehme, Ofri Goldenberg, Yoav Shechtman, Henrik K. Moberg, Christoph Langhammer, Barbora Špačková, Saga Helgadottir, Benjamin Midtvedt, Aykut Argun, Tobias Thalheim, Frank Cichos, Stefano Bo, Lars Hubatsch, Jesus Pineda, Carlo Manzo, Harshith Bachimanchi, Erik Selander, Antoni Homs-Corbera, Martin Fränzl, Kevin de Haan, Yair Rivenson, Zofia Korczak, Caroline Beck Adiels, Mite Mijalkov, Dániel Veréb, Yu-Wei Chang, Joana B. Pereira, Damian Matuszewski, Gustaf Kylberg, Ida-Maria Sintorn, Juan C. Caicedo, Beth A Cimini, Muyinatu A. Lediju Bell, Bruno M. Saraiva, Guillaume Jacquemet, Ricardo Henriques, Wei Ouyang, Trang Le, Estibaliz Gómez-de-Mariscal, Daniel Sage, Arrate Muñoz-Barrutia, Ebba Josefson Lindqvist, Johanna Bergman
arXiv: 2303.03793
Through digital imaging, microscopy has evolved from primarily being a means for visual observation of life at the micro- and nano-scale, to a quantitative tool with ever-increasing resolution and throughput. Artificial intelligence, deep neural networks, and machine learning are all niche terms describing computational methods that have gained a pivotal role in microscopy-based research over the past decade. This Roadmap is written collectively by prominent researchers and encompasses selected aspects of how machine learning is applied to microscopy image data, with the aim of gaining scientific knowledge by improved image quality, automated detection, segmentation, classification and tracking of objects, and efficient merging of information from multiple imaging modalities. We aim to give the reader an overview of the key developments and an understanding of possibilities and limitations of machine learning for microscopy. It will be of interest to a wide cross-disciplinary audience in the physical sciences and life sciences.